Sequential Decision Making via Reinforcement Learning, Generative Models and LLMs/VLMs:
- The Evolving Landscape of LLM-and VLM-Integrated Reinforcement Learning
- Paper | Code
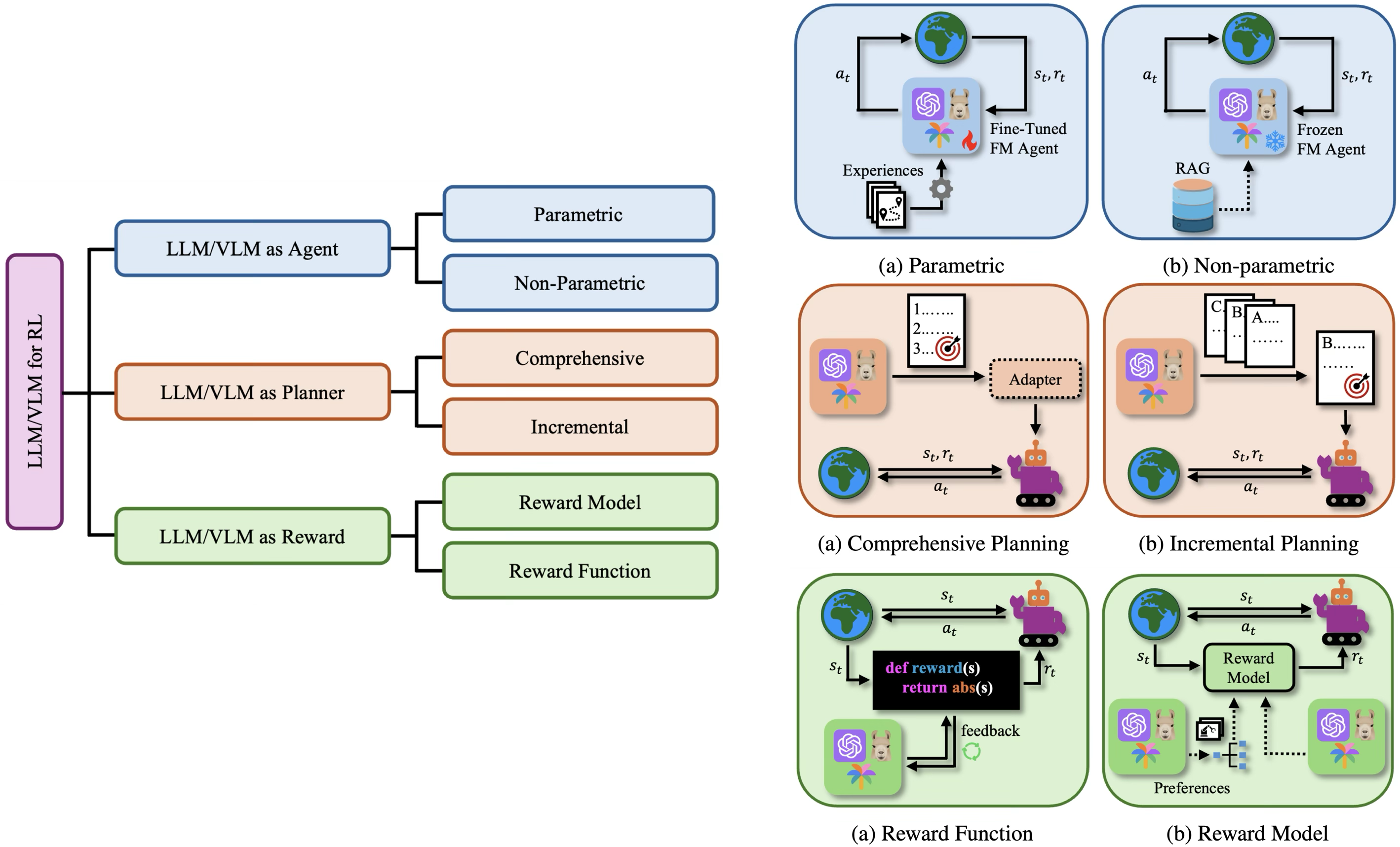
Reinforcement learning (RL) has shown impressive results in sequential decision-making tasks, while Large Language Models (LLMs) and Vision-Language Models (VLMs) have emerged with remarkable capabilities in multimodal understanding and reasoning. This survey reviews representative works where LLMs and VLMs are used to overcome key challenges in RL, such as lack of prior knowledge, long-horizon planning, and reward design. We present a taxonomy categorizing these approaches into three roles: agent, planner, and reward. The survey establishes a framework for integrating LLMs and VLMs into RL, advancing approaches that unify natural language and visual understanding with sequential decision-making.
- A Study of the Efficacy of Generative Flow Networks for Robotics and Machine Fault-Adaptation
- Paper | Code
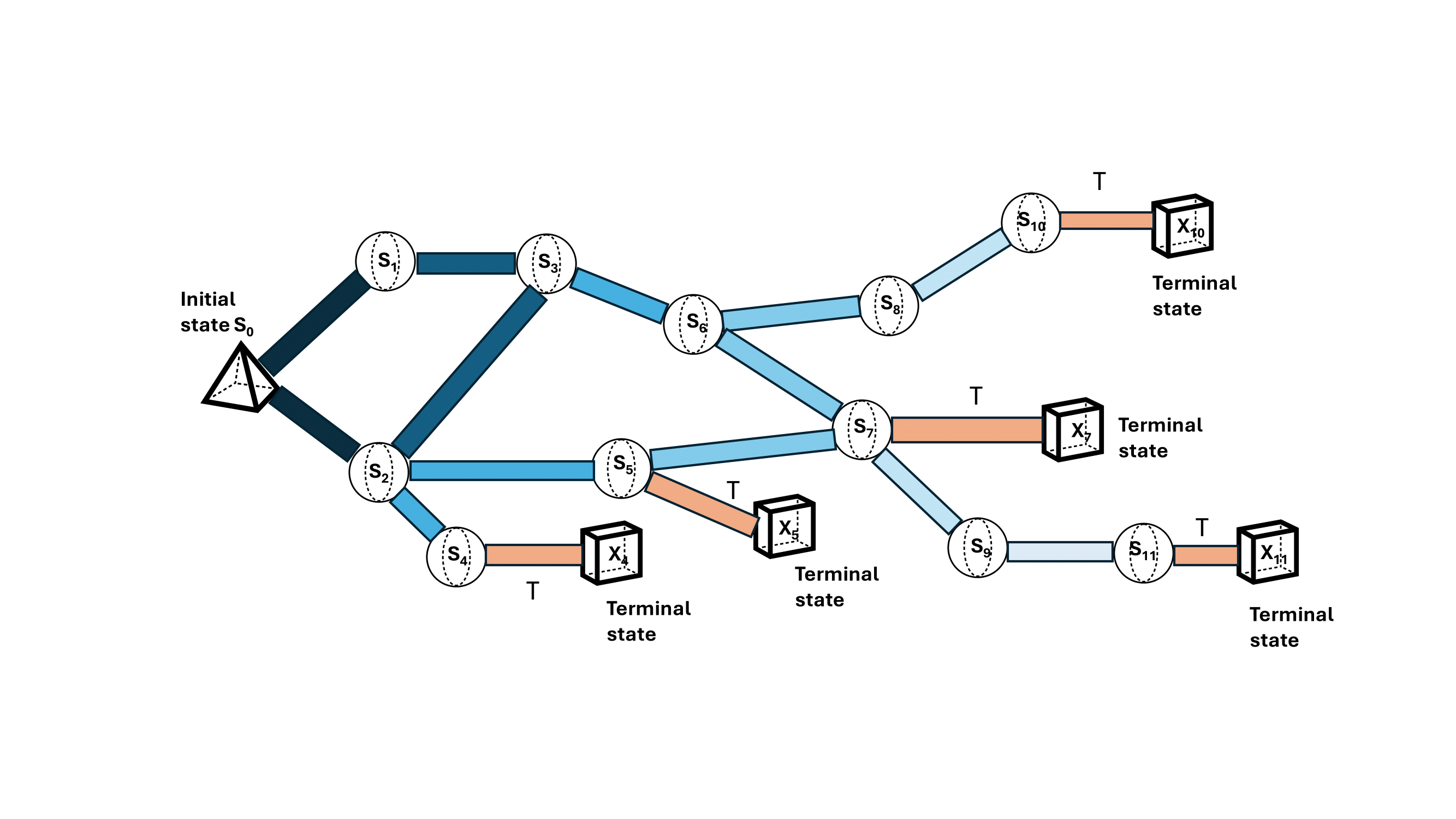
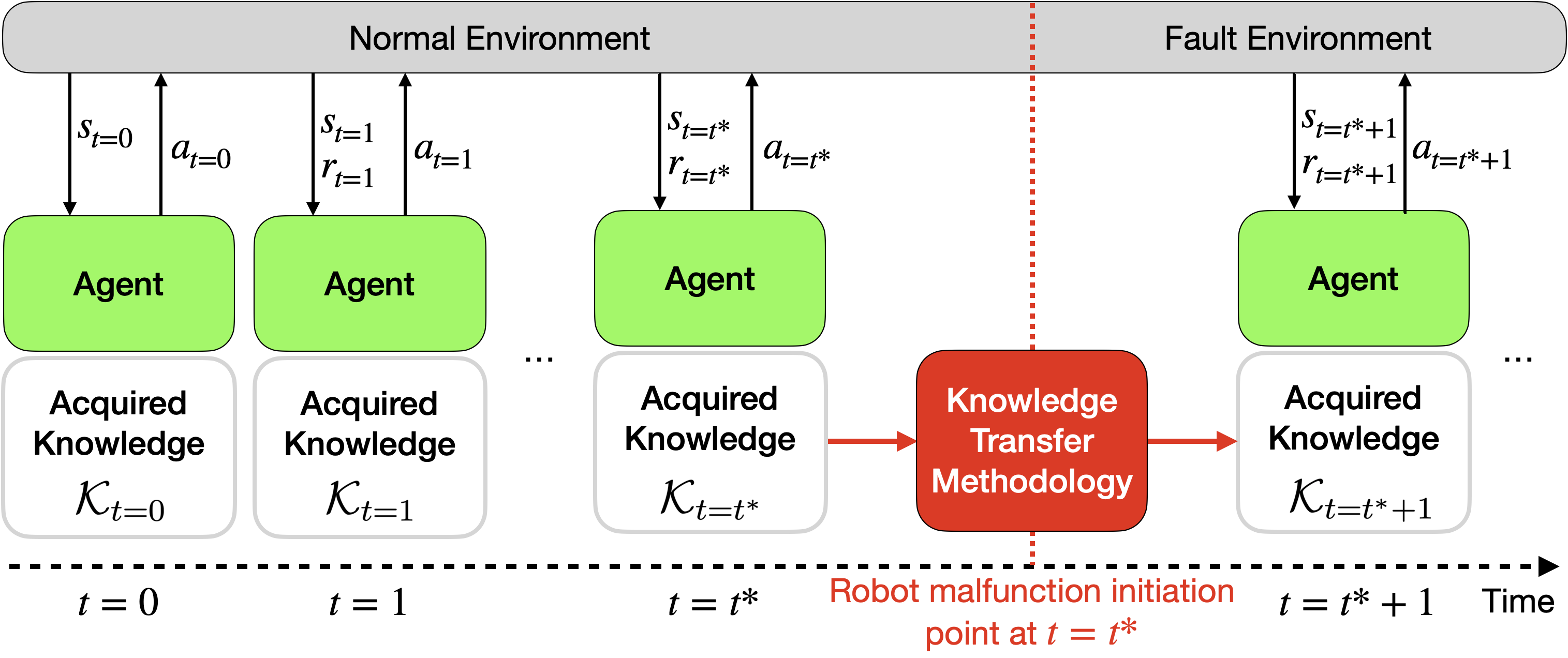
Advancements in robotics enable automation across manufacturing, emergency response, and healthcare. However, robots face challenges in out-of-distribution (OOD) situations, particularly when encountering hardware faults. Current reinforcement learning algorithms show promise but suffer from sample inefficiency and slow adaptation. Our research investigates the efficacy of generative flow networks (CFlowNets) for machine fault adaptation in robotic environments. Using a modified Reacher environment with four distinct fault scenarios, we demonstrate that CFlowNets can add adaptive behaviors under adversarial conditions. Comparative analysis with RL algorithms reveals insights into adaptation speed and sample efficiency. Our experiments confirm CFlowNets' potential for real-world deployment, showing adaptability to maintain functionality during malfunctions.
- Adaptive Iterative Feedback Prompting for Obstacle-Aware Path Planning via LLMs
- Paper | Code
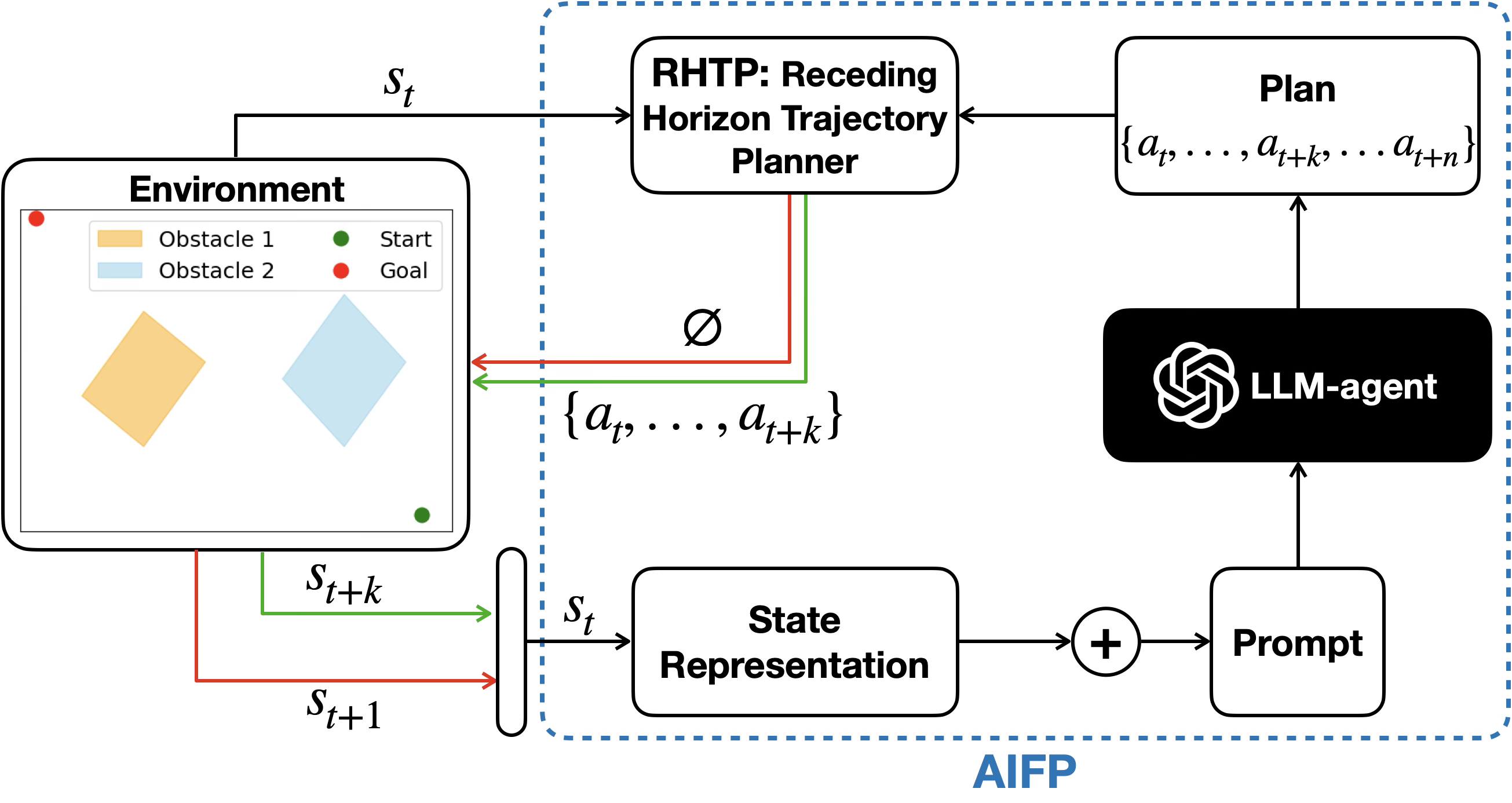
Planning is crucial for agents in complex decision-making tasks, especially in Human-Robot Interaction (HRI) scenarios requiring adaptability in dynamic environments. Large Language Models (LLMs) show promise for enhancing planning through natural language understanding, but their effectiveness is limited by spatial reasoning shortcomings. Existing LLM-based planning frameworks often rely on classical methods or struggle with dynamic environments. We propose the "Adaptive Iterative Feedback Prompting" (AIFP) framework for path planning, where an LLM generates partial trajectories iteratively, evaluated for potential collisions using environmental feedback. AIFP either executes the trajectory or re-plans based on evaluation results. Our preliminary results show AIFP increases baseline success rate by 33.3% and generates efficient, appropriately complex paths, making it promising for dynamic HRI scenarios.
- Enhancing Hardware Fault Tolerance in Autonomous Machines Using Reinforcement Learning Policy Gradient Algorithms
- Paper | Code
The industry is shifting towards autonomous systems capable of detecting and adapting to machine hardware faults. Traditional fault tolerance involves duplicating components and reconfiguring processes, but reinforcement learning (RL) offers a new approach. This paper explores the potential of two RL algorithms, PPO and SAC, for enhancing hardware fault tolerance in machines. Tested in OpenAI Gym environments (Ant-v2, FetchReach-v1) with six simulated faults, results show RL enables rapid adaptation. PPO adapts best by retaining knowledge, while SAC performs better when discarding it, highlighting RL's potential for developing robust, adaptive machines.
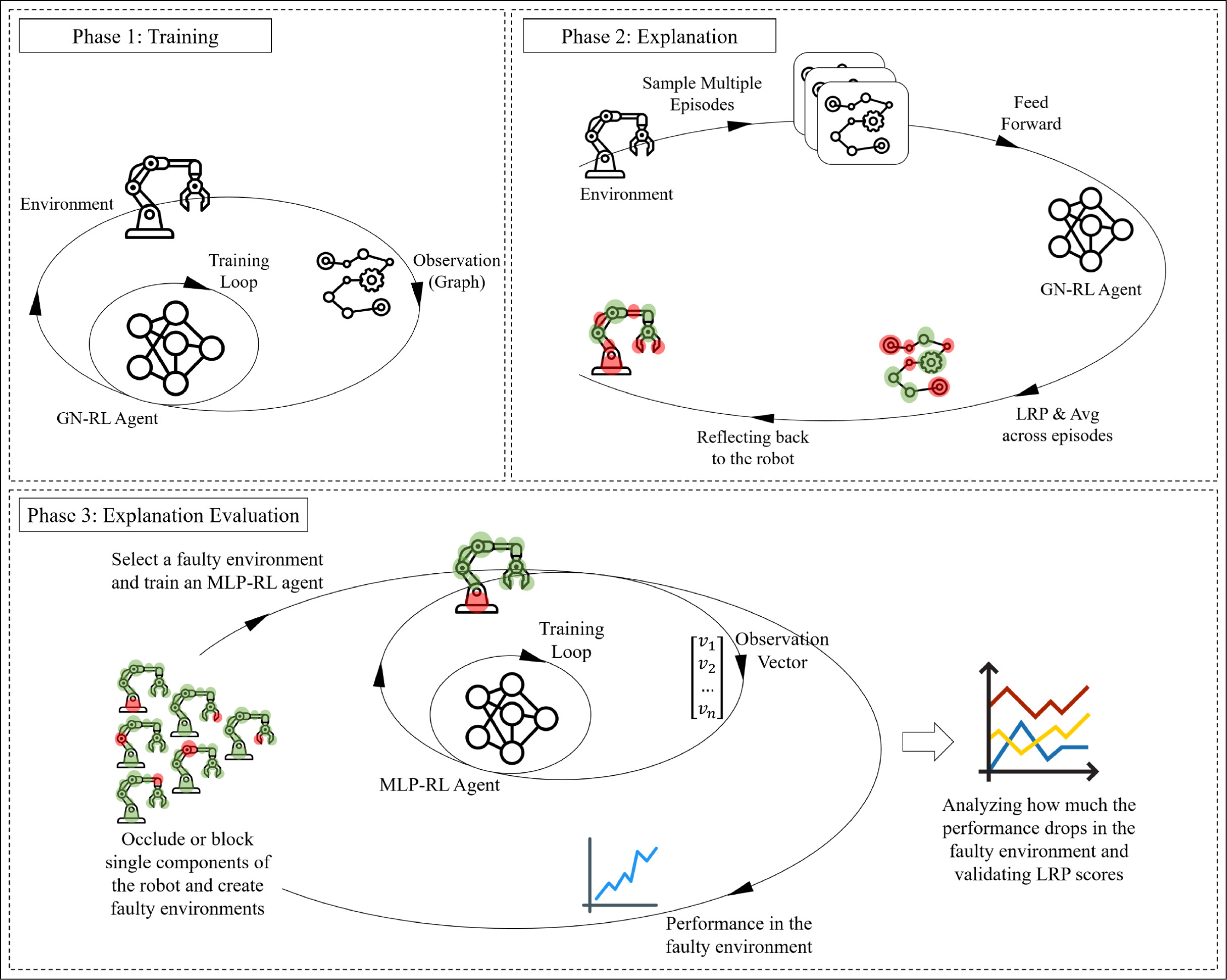
- Explainability of Deep Reinforcement Learning Algorithms in Robotics
- Paper | Code
Deep reinforcement learning (DRL) has been successful in robotics but lacks explainability. This research proposes using Graph Networks and Layer-wise Relevance Propagation (LRP) to analyze the learned representations of a robot's observations. By representing observations as entity-relationship graphs, we can interpret the robot's decision-making process, compare different policies, and understand how the robot recovers from errors. This approach contributes to making DRL in robotics more transparent and understandable.
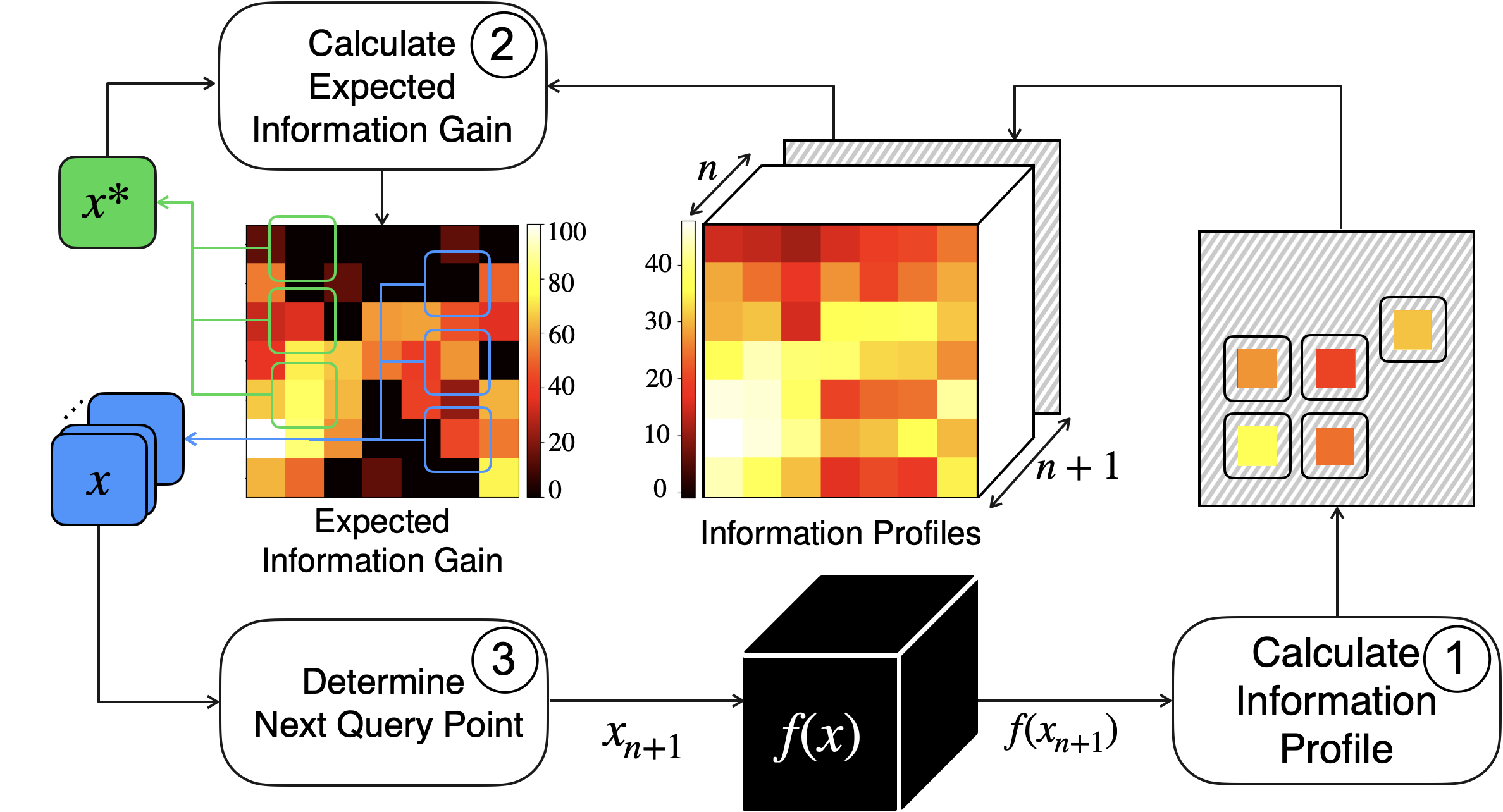
Bayesian Optimization:
- Grey-box Bayesian Optimization
- Paper | Code | Slides
We propose novel grey-box Bayesian optimization algorithms, which focuses on learning domain-specific knowledge inherent to the function being optimized. This leads to designing acquisition functions that incorporate the knowledge into the decision-making process for choosing the next candidate point. In the example provided below, step 1 calculates a credit for each parameter of the candidate point (brighter colors mean more credit). We construct an information profiles that is used for calculating the expected information gain of each parameter in step 2. In step 2, we use the previous version of the expected information gain of the best answer that we have found so far, x_star. The expected informatio gain then tells us the next query point.
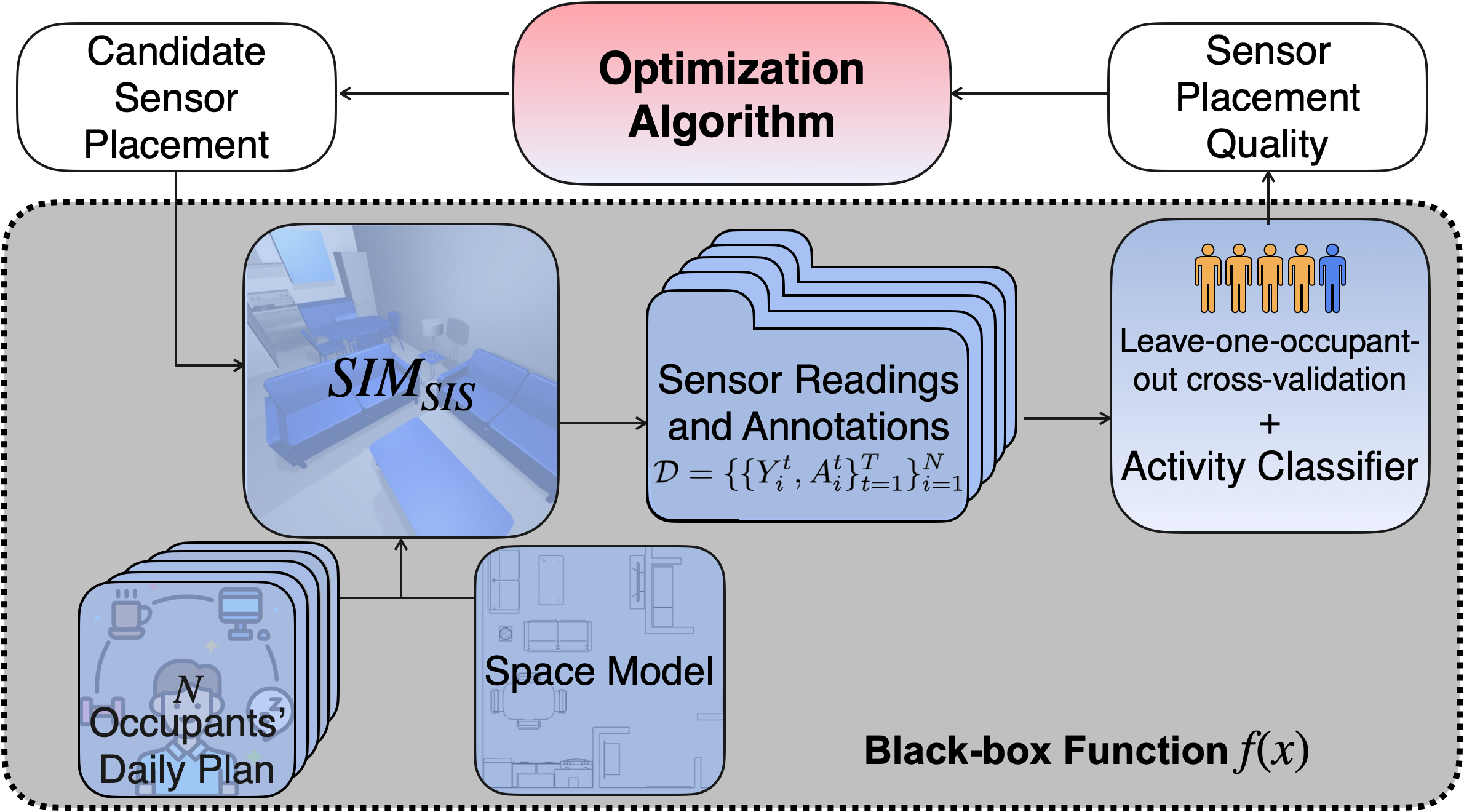
- Simulation-driven Sensor Placement Optimization Framework
- PhD Dissertation | Code
We propose a framework that at its heart, lies an optimization algorithm. The algorithm iteratively observes the previous outcome of a sensor placement and accordingly proposes the next one. The candidate sensor placement goes to a simulation software that produces a synthetic, but realistic datasets according to the occupants daily activity plans, indoor space layout and sensors. The dataset consists of occupants activities and corresponding sensor readings. This dataset is then used by an activity classifier to train and test an activity recognition model. The performance of the activity recognition model is reported as the quality of the candidate sensor placement.
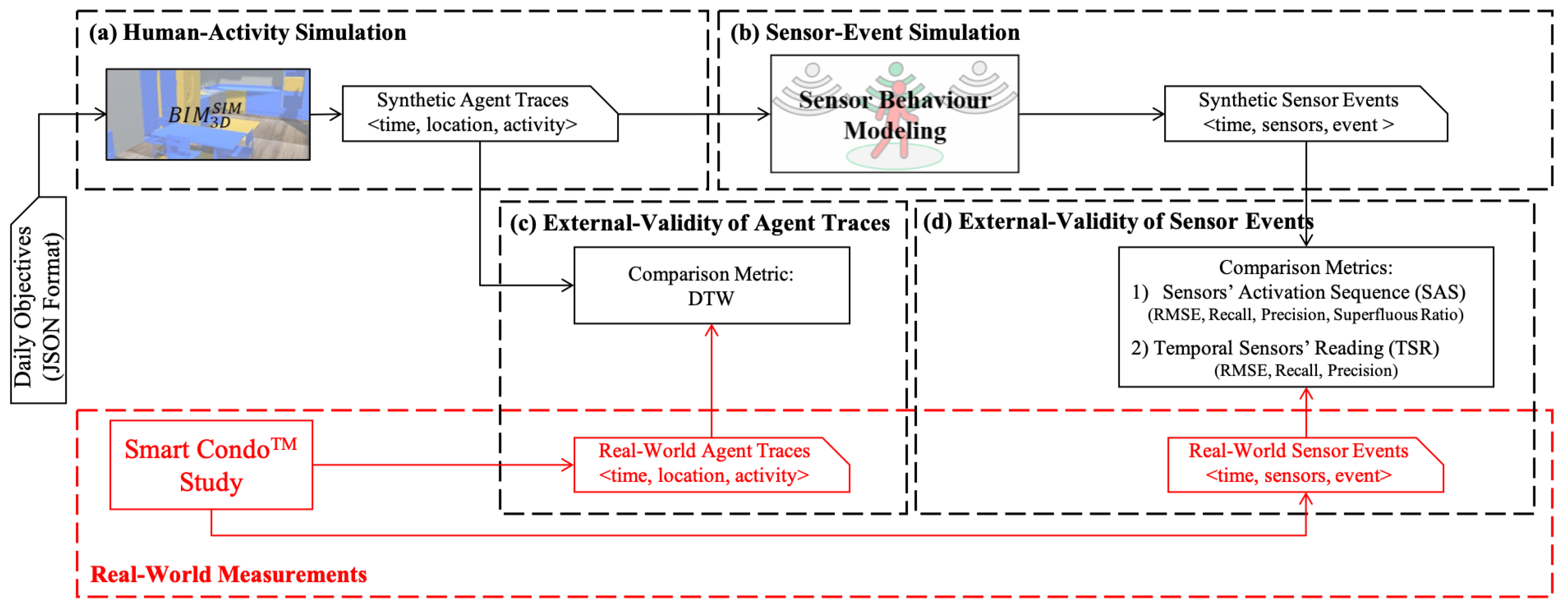
Simulation Methodologies:
- Sim SIS: A Simulation Framework for Smart Indoor Spaces
- Paper | Code
Optimizing sensor placement in smart homes and buildings is challenging due to the time and cost of real-world testing. This research presents a simulation tool called SIMsis that models indoor spaces, occupant activities, and sensor behaviors. SIMsis generates realistic sensor data over time, which can be used to evaluate different sensor configurations without physical experimentation. We tested SIMsis in a smart home setting (Real-World Measurements) and found it effectively simulates real-world conditions, making it a valuable tool for developing and deploying sensor-based applications.
golestan@ualberta.ca
AI Computing System Research Lab
Huawei Canada